library(tidyverse)
library(survival)
library(survminer)
library(gtsummary)
theme_gtsummary_journal("lancet")
theme_gtsummary_language("zh-cn")关于survial包做生存分析的记录
基础知识
生存分析
生存分析(survival analysis)是生物医学研究中常用的分析方法。在队列随访研究中,我们会事先定义一些观察终点,比如肿瘤复发、患者死亡、血压达标等,这些终点称为事件(event)。从研究开始到发生事件的时间间隔称为生存时间(survival time),某些场景下也称为失效时间(failure time)。由于生存时间数据具有以下两个特点,所以提出生存分析这一特殊的分析方法: (1)偏态分布:生存时间通常具有明显的偏态分布,有正态分布假设的统计方法不能适用。 (2)删失(censoring):研究对象在观察时间内没有发生事件称为删失。一种情况是研究对象在中途失访或退出,导致没有观察到事件;另一种情况是超过了最长的随访时间事件仍未发生。删失数据是一种不完整数据,是生成分析独有的重要组成部分。
包里的常用函数
Surv() 函数主要用于对时间和状态变量进行转换,主要作为模型的自变量,放在模型方程左边,例如:
Surv(time, status )右截断数据(right censored data)在进行随访观察中,研究对象观察的起始时间已知,但终点事件发生的时间未知,无法获取具体的生存时间,只知道生存时间大于观察时间,这种类型的生存时间称为右删失。Surv(time, endpoint=='death')状态变量是因子或字符的时候Surv(t1, t2, status)连续的过程变量Surv(t1, ind, type='left')左删失
左删失(Left censored)假设研究对象在某一时刻开始进入研究接受观察,但是在该时间点之前,研究所感兴趣的时间点已经发生,但无法明确具体时间,这种类型即为左删失数据。例如,某项关于脑卒中复发危险因素的研究,生存时间规定为从第一次脑卒中发病到下一次脑卒中发病之间的时间间隔。在研究起始时刻对研究对象进行问卷调查,询问是否发生过脑卒中,以及第一次脑卒中发病的时间,如果研究对象回答“发生过脑卒中。
aareg() Aalen’s additive regression model.
coxph() Cox比例风险模型
coxph(Surv(time, status) ~ x, data=aml)-标准cox模型coxph(Surv(t1, t2, stat) ~ (age + surgery) * transplant)-时间相关协变量y <- Surv(t1, t2, stat)coxph(y ~ strata(inst) * sex + age + treat)-分层模型,每个机构有不同的基线和机构对性别的交互作用。coxph(y ~ offset(x1) + x2)-设置x1为已经系数项,不估计其系数。
cox.zph() 基于加权残差的cox模型的比例风险检验。
fit <- coxph(Surv(futime, fustat) ~ age + ecog.ps, data = ovarian)
temp <- cox.zph(fit)
print(temp) %>%
knitr::kable() # display the results chisq df page 0.698 1 0.40 ecog.ps 2.371 1 0.12 GLOBAL 3.633 2 0.16
| chisq | df | p | |
|---|---|---|---|
| age | 0.698 | 1 | 0.404 |
| ecog.ps | 2.371 | 1 | 0.124 |
| GLOBAL | 3.633 | 2 | 0.163 |
- tcut() -
rcut()-在不丢失连续性特征的情况下分段,如
heart %>%
select(age) %>%
mutate(cut = cut(age + 40, c(0, 50, 70)), tcut = tcut(age + 40, c(0, 50, 70))) %>%
head(10) %>%
knitr::kable()| age | cut | tcut |
|---|---|---|
| -17.16 | (0,50] | 22.8 |
| 3.84 | (0,50] | 43.8 |
| 6.30 | (0,50] | 46.3 |
| 6.30 | (0,50] | 46.3 |
| -7.74 | (0,50] | 32.3 |
| -7.74 | (0,50] | 32.3 |
| -27.21 | (0,50] | 12.8 |
| 6.59 | (0,50] | 46.6 |
| 2.87 | (0,50] | 42.9 |
| 2.87 | (0,50] | 42.9 |
- pyears() -个体生存情况分析,比如分别计算
heart数据集里面手术组和非手术组各年龄组的死亡率。
fit1 <- pyears(Surv(stop/365.25, event) ~ cut(age + 48, c(0, 50, 60, 70, 100)) +
surgery, data = heart, scale = 1)
fit1$event/fit1$pyears# surgery
# cut(age + 48, c(0, 50, 60, 70, 100)) 0 1
# (0,50] 0.707 0.289
# (50,60] 1.778 0.779
# (60,70] 4.081 NaN
# (70,100] NaN NaN- survexp() 计算指定对象的预期生存率
# Estimate of conditional survival
fit1 <- survexp(futime ~ 1, rmap = list(sex = "male", year = accept.dt, age = (accept.dt -
birth.dt)), method = "conditional", data = jasa)
summary(fit1, times = 1:10 * 182.5, scale = 365) #expected survival by 1/2 years# Call: survexp(formula = futime ~ 1, data = jasa, rmap = list(sex = "male",
# year = accept.dt, age = (accept.dt - birth.dt)), method = "conditional")
#
# time n.risk survival
# 0.5 41 0.996
# 1.0 28 0.993
# 1.5 21 0.989
# 2.0 16 0.986
# 2.5 13 0.983
# 3.0 8 0.980
# 3.5 7 0.977
# 4.0 3 0.972
# 4.5 1 0.969# Estimate of expected survival stratified by prior surgery
survexp(~surgery, rmap = list(sex = "male", year = accept.dt, age = (accept.dt -
birth.dt)), method = "ederer", data = jasa, times = 1:10 * 182.5)# Call:
# survexp(formula = ~surgery, data = jasa, rmap = list(sex = "male",
# year = accept.dt, age = (accept.dt - birth.dt)), times = 1:10 *
# 182.5, method = "ederer")
#
# age ranges from 8.8 to 64.4 years
# male: 103 female: 0
# date of entry from 1967-09-13 to 1974-03-22
#
# time nrisk1 nrisk2 surgery=0 surgery=1
# 182 87 16 0.996 0.996
# 365 87 16 0.991 0.993
# 548 87 16 0.987 0.989
# 730 87 16 0.982 0.985
# 912 87 16 0.978 0.981
# 1095 87 16 0.973 0.977
# 1278 87 16 0.968 0.973
# 1460 87 16 0.963 0.969
# 1642 87 16 0.958 0.964
# 1825 87 16 0.952 0.960## Compare the survival curves for the Mayo PBC data to Cox model fit
pfit <- coxph(Surv(time, status > 0) ~ trt + log(bili) + log(protime) + age + platelet,
data = pbc)
plot(survfit(Surv(time, status > 0) ~ trt, data = pbc), mark.time = FALSE)
lines(survexp(~trt, ratetable = pfit, data = pbc), col = "purple")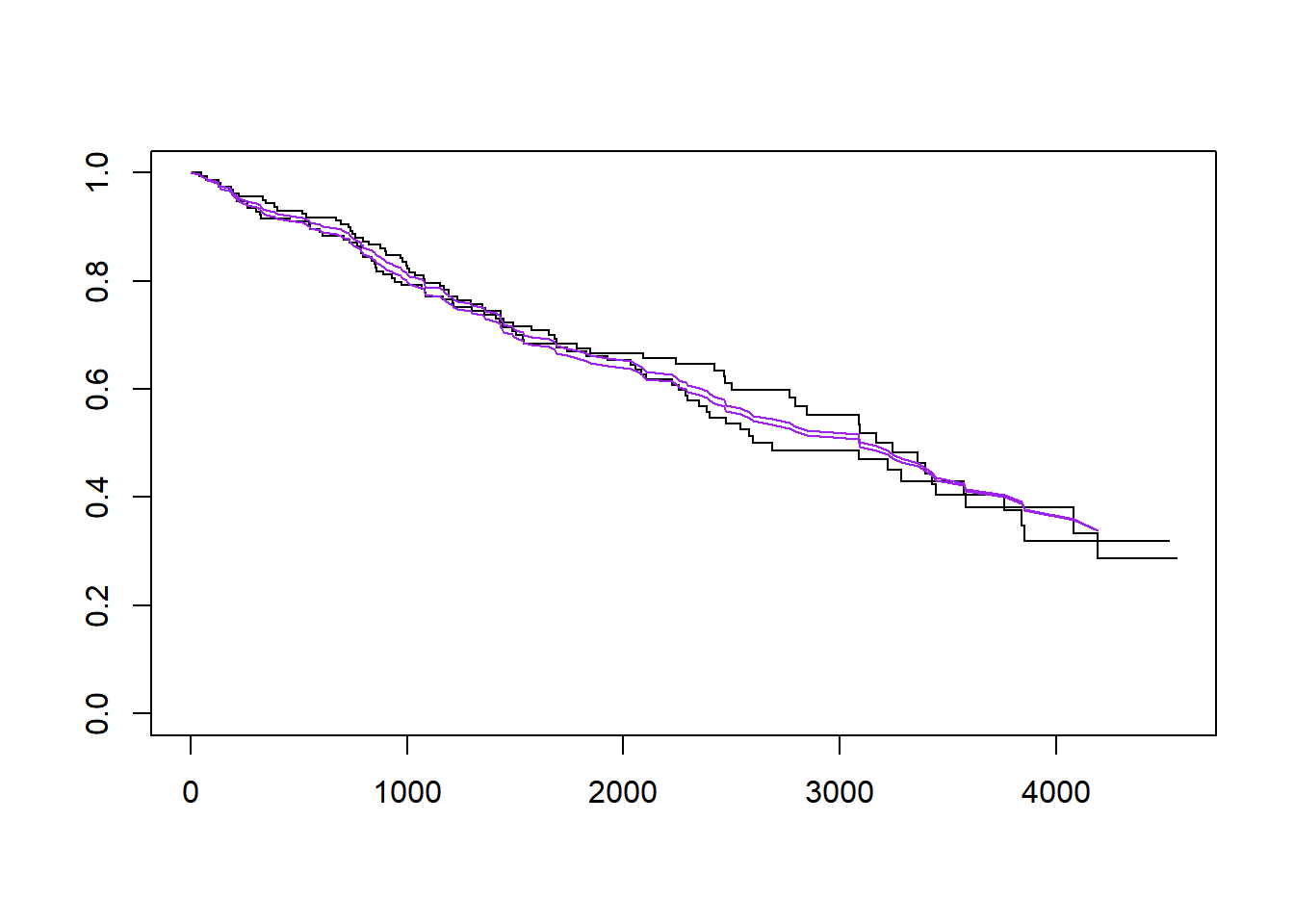
- survdiff() -使用\(G^\rho\)检验,比较两组或多组生存曲线的差异。
# US mortality tables
expect <- survexp(futime ~ 1, data = jasa, cohort = FALSE, rmap = list(age = (accept.dt -
birth.dt), sex = 1, year = accept.dt), ratetable = survexp.us)
## actual survival is much worse (no surprise)
survdiff(Surv(jasa$futime, jasa$fustat) ~ offset(expect))# Call:
# survdiff(formula = Surv(jasa$futime, jasa$fustat) ~ offset(expect))
#
# Observed Expected Z p
# 75.000 0.644 -92.681 0.000survreg() 参数生存回归模型,即把自变量做对数转换或其他转换
survreg(Surv(time, stat) ~ x, dist='loglogistic'-拟合log-logistic分布模型
数学符号定义
- \(risk set\) 在时间事件分析中,给定的对象只在制定的时间范围内观测,例如,研究1990年到2000年的接受某种治疗方法的患者10年内的生存情况,队列中1990年接受治疗的将有10年的潜在观测期,但1995年后的只有5年的观测期。设\(Y_i(t),i=1,...n\)为对象\(i\)在\(t\)时刻观测到“事件”发生。\(Ni(t)\)为\(t\)时刻时观测到发生“事件”发生的对象数,“事件”可能多次发生也可能只发生一次。那么到\(t\)时刻时发生“事件”的总数为\(\overline{N}(t)=\sum{N_i(t)}\),在\(t\)时刻发生“事件”的对象数为\(\overline{Y}(t)=\sum{Y_i(t)}\)。对象的事件相关协变量为\(X_i(t)\)。\(d(t)\)为“事件”在\(t\)时刻的瞬时发生率.
生存曲线
单事件
通常用,\(t\)时刻事的事件发生概率的乘积的Kaplan-Meier曲线来描述生存数据。
\[\begin{align} \hat{S}_{KM}(t)=\prod_{S<t}\frac{\overline{N}(ts)-d(s)}{\overline{Y}(s)} \end{align}\]